

'%3e%3cpath%20d='M21.0949%203.79395L13.9961%209.82854H21.0949V3.79395Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M13.998%209.82854L7.44531%203.79395V9.82854H13.998Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M13.9961%202.69922V25.1919'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M20.5488%2016.4113L13.9961%209.82812V18.2217L20.5488%2024.0918V16.4113Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M7.44531%2016.4113L13.998%209.82812V18.0526L7.44531%2024.0918V16.4113Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M4.71094%209.82812V18.6057H7.44125V16.4113L13.9941%209.82812H4.71094Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M13.9961%209.82812L20.5488%2016.4113V18.6057H23.2792V9.82812H13.9961Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3c/g%3e%3c/svg%3e)

'%3e%3cmask%20id='mask0_21456_29260'%20style='mask-type:luminance'%20maskUnits='userSpaceOnUse'%20x='0'%20y='0'%20width='28'%20height='28'%3e%3cpath%20d='M27.5%200.5H0.5V27.5H27.5V0.5Z'%20fill='white'/%3e%3c/mask%3e%3cg%20mask='url(%23mask0_21456_29260)'%3e%3cpath%20d='M14%2027.5C13.4854%2024.1035%2011.8974%2020.9608%209.46828%2018.5317C7.03922%2016.1026%203.89651%2014.5146%200.5%2014C3.89651%2013.4854%207.03922%2011.8974%209.46828%209.46828C11.8974%207.03922%2013.4854%203.89651%2014%200.5C14.5147%203.89644%2016.1028%207.03905%2018.5318%209.46816C20.9609%2011.8972%2024.1035%2013.4853%2027.5%2014C24.1035%2014.5147%2020.9609%2016.1028%2018.5318%2018.5318C16.1028%2020.9609%2014.5147%2024.1035%2014%2027.5Z'%20fill='url(%23paint0_linear_21456_29260)'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_21456_29260'%20x1='9.5'%20y1='9.5'%20x2='20.75'%20y2='21.875'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23F0DCD6'/%3e%3cstop%20offset='0.914506'%20stop-color='%231D6DFF'/%3e%3c/linearGradient%3e%3cclipPath%20id='clip0_21456_29260'%3e%3crect%20width='28'%20height='28'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M22.8019%2011.2412L23.5234%2011.6807V12.0103L23.3172%2012.7796L14.5579%2014.9771L13.7344%2012.7951L22.8019%2011.2412Z'%20fill='%23D97757'/%3e%3cpath%20d='M19.5236%204.77832L20.5322%205.00396L20.8%205.35575L21.0552%206.19876L20.9494%206.73644L15.0712%2015.3068L13.1133%2013.2191L18.5338%205.63471L19.5236%204.77832Z'%20fill='%23D97757'/%3e%3cpath%20d='M14.4577%203.43951L15.0761%203L15.5912%203.21976L16.1065%203.9889L14.6949%2013.0345L13.7364%2012.3397L13.3242%2011.131L14.0456%204.31853L14.4577%203.43951Z'%20fill='%23D97757'/%3e%3cpath%20d='M7.84766%203.5851L8.48285%202.7199L8.89716%202.61914L9.71923%202.74717L10.125%203.08581L13.0815%2010.0748L14.1509%2013.3954L12.8997%2014.1372L8.13117%204.91019L7.84766%203.5851Z'%20fill='%23D97757'/%3e%3cpath%20d='M4.77232%208.38688L4.56641%207.50742L5.18478%206.73828L5.90613%206.84816H6.11223L10.4403%2010.2544L11.78%2011.3531L13.6349%2012.8914L12.6044%2014.7594L11.6769%2013.9903L11.0586%2013.331L5.08168%208.82593L4.77232%208.38688Z'%20fill='%23D97757'/%3e%3cpath%20d='M3.53288%2014.0982L3.06641%2013.5489L3.06647%2013.0601L3.53288%2012.8896L8.78833%2013.2193L13.9408%2013.6588L13.7736%2014.7528L3.94502%2014.2082L3.53288%2014.0982Z'%20fill='%23D97757'/%3e%3cpath%20d='M6.62378%2019.8178H5.59334L5.18359%2019.3146V18.7132L6.93299%2017.3946L14.045%2012.5674L14.7648%2013.8785L6.62378%2019.8178Z'%20fill='%23D97757'/%3e%3cpath%20d='M8.57739%2022.8884L8.16518%2022.9984L7.54688%2022.6687L7.64995%2022.1193L13.7299%2013.5488L14.5543%2014.7574L10.0201%2021.1305L8.57739%2022.8884Z'%20fill='%23D97757'/%3e%3cpath%20d='M13.7361%2023.9861L13.4271%2024.4257L12.8088%2024.6454L12.2935%2024.2058L11.9844%2023.5466L13.5301%2014.6465L14.4576%2014.7563L13.7361%2023.9861Z'%20fill='%23D97757'/%3e%3cpath%20d='M18.9869%2021.5713V22.4503L18.8838%2022.7799L18.4716%2022.9997L17.7503%2022.8974L12.7969%2015.0367L14.7617%2013.4404L16.4104%2016.6269L16.5652%2017.7805L18.9869%2021.5713Z'%20fill='%23D97757'/%3e%3cpath%20d='M21.3629%2020.2507L21.4659%2020.8L21.1568%2021.2396L20.8476%2021.1297L19.0958%2019.8112L16.4165%2017.284L14.3555%2015.7457L14.9736%2013.6582L16.0041%2014.3175L16.6226%2015.5259L21.3629%2020.2507Z'%20fill='%23D97757'/%3e%3cpath%20d='M20.0232%2014.6482L22.5995%2014.8679L23.2178%2015.3074L23.6299%2015.9667V16.441L22.4964%2016.9556L16.7256%2015.4173L14.3555%2015.3074L14.9737%2013L16.6226%2014.3185L20.0232%2014.6482Z'%20fill='%23D97757'/%3e%3c/g%3e%3c/svg%3e)

In global video distribution, a core challenge is ensuring subtitles and dubs are not only accurate in meaning but also natural in rhythm for the local audience. A fast-paced English narration directly translated into Chinese can leave viewers feeling breathless.
Today, we delve into the core technology solving this: the Cross-Lingual Speech Rate and Pause Penalty Algorithm. Instead of stretching audio, it acts like a bilingual rhythm maestro, intelligently modulating the "breath" of language.
The Core Problem: The Natural Gap in Speech Rate
Every language has its inherent information density and pronunciation rhythm. A key observational metric is the Cross-Lingual Speech Rate Ratio (base):
base = S_theo / T_theoWhere:
S_theo: Theoretical speech rate of the source language (e.g., English) in words per minute.T_theo: Theoretical speech rate of the target language (e.g., Chinese) in words per minute.
This statistically derived
base value (e.g., 1.3) indicates that English is typically spoken 1.3 times faster than Chinese. This is our baseline expectation.The Core Challenge: Handling Deviant "Rhythmic Personalities"
Real speech is full of personality. An excited speaker's actual rate (
S_act) might be much faster than their language's norm (S_theo). Simply adjusting the target rate by the ratio S_act / S_theo (which we call speed_sl_ratio) would cause the target speech rate to spiral out of control.Our Solution: Establishing a Speech Rate "Safe Zone"
Our first innovation is introducing an Asymmetric Compression Function that compresses the raw
speed_sl_ratio into a reasonable interval [sl_min, sl_max] (e.g., [0.9, 1.2]), yielding speed_sl_penalized_ratio.It is mathematically expressed as:
Let
r = speed_sl_ratio, delta = r - 1- When speech is fast (delta > 0):
r_pen = 1 + delta / (1 + gamma_pos * delta)gamma_pos = 1 / (sl_max - 1)- When speech is slow (delta < 0):
r_pen = 1 + delta / (1 + gamma_neg * (-delta))gamma_neg = 1 / (1 - sl_min)Finally,
speed_sl_penalized_ratio = clamp(r_pen, sl_min, sl_max)The elegance of this formula lies in:
- It gently "pulls" extreme values back into the safe zone, avoiding wild output fluctuations.
- It changes smoothly and linearly near the safe zone, preventing audible artifacts.
- It enables asymmetric control via
gamma_posandgamma_neg, allowing different constraint intensities for "too fast" and "too slow."
We now have a stable target speech rate:
T_act = T_theo * speed_sl_penalized_ratio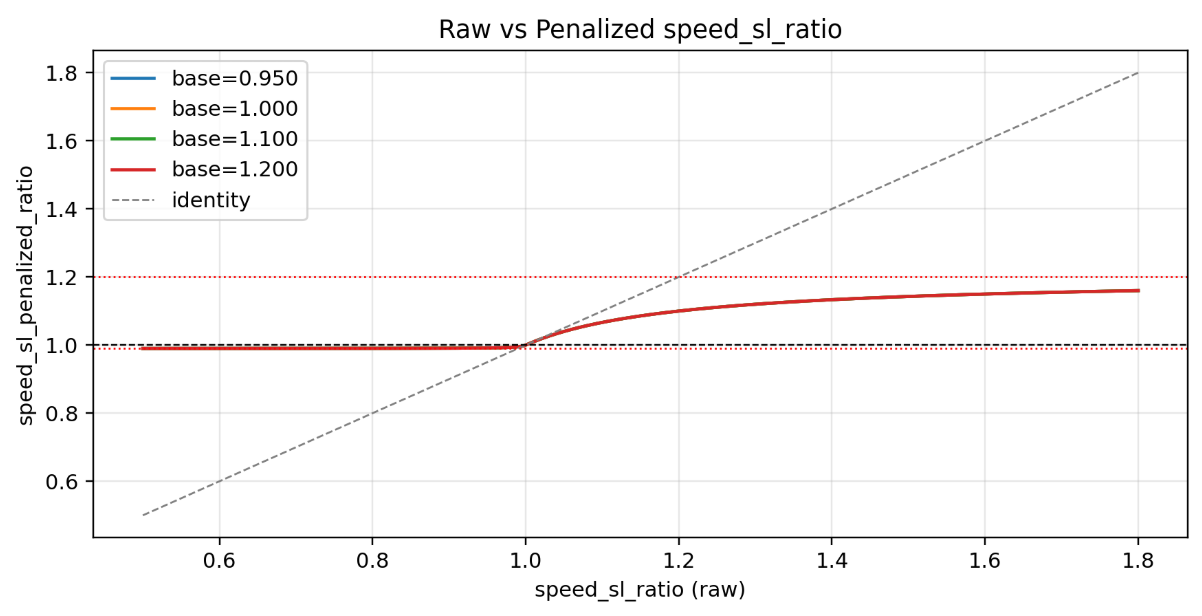
The Masterstroke: Transforming Rhythm Deviation into "Breath" Adjustment
So, where does the penalized rhythmic difference go? It is cleverly channeled into the pauses between phrases. This is the algorithm's second innovation.
We introduce a core variable: the Pause Scaling Factor (
eff_ratio).eff_ratio = base * (speed_sl_ratio / speed_sl_penalized_ratio)This formula is the bridge for rhythm conversion:
- If
speed_sl_ratio > speed_sl_penalized_ratio(source was too fast and got compressed), theneff_ratio > base. This means the system will lengthen pauses to compensate for potential rushed feelings caused by rate suppression, creating digestion time for the viewer. - If
speed_sl_ratio < speed_sl_penalized_ratio(source was too slow), theneff_ratio < base. The system will shorten pauses to prevent a dragging rhythm.
Finally, each eligible pause tag
<break time="Xms"> is scaled by eff_ratio:new_time = clamp(round(X * eff_ratio), min_pause, MAX_BREAK_MS)
System Workflow & Meticulous Craftsmanship
The entire system workflow is clear and robust:
- Initialize: Load the language pair base ratio
base. - Calculate Baseline:
S_theo = T_theo * base - Analyze Deviation:
speed_sl_ratio = S_act / S_theo - Safe Compression:
speed_sl_penalized_ratio = compress_asym(speed_sl_ratio) - Rhythm Conversion:
eff_ratio = base * (speed_sl_ratio / speed_sl_penalized_ratio) - Boundary Handling: Fine-tune, clip, and "snap-to-1" the
eff_ratio(set to 1 if very close, removing micro-jitter). - Apply Pauses: Scale all pauses longer than the language-specific threshold (e.g., 80ms for Chinese).
We perfect the details:
- Threshold Protection: Ignore micro-pauses to preserve natural speech cadence.
- Hard Boundary Guarantee:
eff_ratiois strictly bounded by[0.65, 1.50]to handle extremes. - OutputQuantization: All times are quantized to multiples of 10ms, ensuring stable front-end display (e.g., 1230ms displays as 1.23s).
Optimized Example (with rhythm-adjusted samples)
The following demonstrates how the same narration adapts naturally across languages.
Pause durations are automatically optimized by the algorithm to maintain natural pacing and listener comfort.
English (source):
["True voice translation captures the soul of speech,<break time="640ms"/> not just converting words, but the living rhythm between them.", "Each language breathes at its own unique pace,<break time="519ms"/> and now we can teach machines to understand the stance of human expression."]
Chinese:
["真正的语音翻译能捕捉到语言的灵魂,<break time=\"980ms\"/>不仅仅是将词语转换,而是传递它们之间鲜活的韵律。", "每种语言都有其独特的呼吸节奏,<break time="790ms"/> 现在我们可以教机器理解人类表达的立场。"]
German:
["Echte Sprachübersetzung erfasst die Seele der Rede,<break time="500ms"/> nicht nur indem sie Worte übersetzt, sondern auch den lebendigen Rhythmus dazwischen.", "Jede Sprache atmet in ihrem ganz eigenen Rhythmus,<break time="400ms"/> und jetzt können wir Maschinen beibringen, die Haltung menschlicher Ausdrucksweise zu verstehen."]
These multilingual examples highlight the algorithm’s subtle artistry:
it preserves meaning while dynamically adapting timing and pauses — letting each language breathe in its own natural rhythm.
In Conclusion
Our algorithm achieves a sophisticated "rhythm decoupling":
- Text Content is faithfully translated, unaffected.
- Main Speech Rate is constrained within a comfortable safe zone.
- Pause Rhythm shoulders all remaining adjustment tasks, becoming the "magician" shaping the final auditory experience.
Through the core variable
eff_ratio, we successfully translate the "rhythmic personality" of the source language into "breathing instructions" for the target language. This is not just a technology; it's an art form that enables machines to understand and reproduce the beauty of human speech prosody.Dingyi
Behind VMEG stands a passionate team of creatives, engineers, and language lovers. At the crossroads of AI and storytelling, they craft tools that bridge languages and cultures.