

'%3e%3cpath%20d='M21.0949%203.79395L13.9961%209.82854H21.0949V3.79395Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M13.998%209.82854L7.44531%203.79395V9.82854H13.998Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M13.9961%202.69922V25.1919'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M20.5488%2016.4113L13.9961%209.82812V18.2217L20.5488%2024.0918V16.4113Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M7.44531%2016.4113L13.998%209.82812V18.0526L7.44531%2024.0918V16.4113Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M4.71094%209.82812V18.6057H7.44125V16.4113L13.9941%209.82812H4.71094Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M13.9961%209.82812L20.5488%2016.4113V18.6057H23.2792V9.82812H13.9961Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3c/g%3e%3c/svg%3e)

'%3e%3cmask%20id='mask0_21456_29260'%20style='mask-type:luminance'%20maskUnits='userSpaceOnUse'%20x='0'%20y='0'%20width='28'%20height='28'%3e%3cpath%20d='M27.5%200.5H0.5V27.5H27.5V0.5Z'%20fill='white'/%3e%3c/mask%3e%3cg%20mask='url(%23mask0_21456_29260)'%3e%3cpath%20d='M14%2027.5C13.4854%2024.1035%2011.8974%2020.9608%209.46828%2018.5317C7.03922%2016.1026%203.89651%2014.5146%200.5%2014C3.89651%2013.4854%207.03922%2011.8974%209.46828%209.46828C11.8974%207.03922%2013.4854%203.89651%2014%200.5C14.5147%203.89644%2016.1028%207.03905%2018.5318%209.46816C20.9609%2011.8972%2024.1035%2013.4853%2027.5%2014C24.1035%2014.5147%2020.9609%2016.1028%2018.5318%2018.5318C16.1028%2020.9609%2014.5147%2024.1035%2014%2027.5Z'%20fill='url(%23paint0_linear_21456_29260)'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_21456_29260'%20x1='9.5'%20y1='9.5'%20x2='20.75'%20y2='21.875'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23F0DCD6'/%3e%3cstop%20offset='0.914506'%20stop-color='%231D6DFF'/%3e%3c/linearGradient%3e%3cclipPath%20id='clip0_21456_29260'%3e%3crect%20width='28'%20height='28'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M22.8019%2011.2412L23.5234%2011.6807V12.0103L23.3172%2012.7796L14.5579%2014.9771L13.7344%2012.7951L22.8019%2011.2412Z'%20fill='%23D97757'/%3e%3cpath%20d='M19.5236%204.77832L20.5322%205.00396L20.8%205.35575L21.0552%206.19876L20.9494%206.73644L15.0712%2015.3068L13.1133%2013.2191L18.5338%205.63471L19.5236%204.77832Z'%20fill='%23D97757'/%3e%3cpath%20d='M14.4577%203.43951L15.0761%203L15.5912%203.21976L16.1065%203.9889L14.6949%2013.0345L13.7364%2012.3397L13.3242%2011.131L14.0456%204.31853L14.4577%203.43951Z'%20fill='%23D97757'/%3e%3cpath%20d='M7.84766%203.5851L8.48285%202.7199L8.89716%202.61914L9.71923%202.74717L10.125%203.08581L13.0815%2010.0748L14.1509%2013.3954L12.8997%2014.1372L8.13117%204.91019L7.84766%203.5851Z'%20fill='%23D97757'/%3e%3cpath%20d='M4.77232%208.38688L4.56641%207.50742L5.18478%206.73828L5.90613%206.84816H6.11223L10.4403%2010.2544L11.78%2011.3531L13.6349%2012.8914L12.6044%2014.7594L11.6769%2013.9903L11.0586%2013.331L5.08168%208.82593L4.77232%208.38688Z'%20fill='%23D97757'/%3e%3cpath%20d='M3.53288%2014.0982L3.06641%2013.5489L3.06647%2013.0601L3.53288%2012.8896L8.78833%2013.2193L13.9408%2013.6588L13.7736%2014.7528L3.94502%2014.2082L3.53288%2014.0982Z'%20fill='%23D97757'/%3e%3cpath%20d='M6.62378%2019.8178H5.59334L5.18359%2019.3146V18.7132L6.93299%2017.3946L14.045%2012.5674L14.7648%2013.8785L6.62378%2019.8178Z'%20fill='%23D97757'/%3e%3cpath%20d='M8.57739%2022.8884L8.16518%2022.9984L7.54688%2022.6687L7.64995%2022.1193L13.7299%2013.5488L14.5543%2014.7574L10.0201%2021.1305L8.57739%2022.8884Z'%20fill='%23D97757'/%3e%3cpath%20d='M13.7361%2023.9861L13.4271%2024.4257L12.8088%2024.6454L12.2935%2024.2058L11.9844%2023.5466L13.5301%2014.6465L14.4576%2014.7563L13.7361%2023.9861Z'%20fill='%23D97757'/%3e%3cpath%20d='M18.9869%2021.5713V22.4503L18.8838%2022.7799L18.4716%2022.9997L17.7503%2022.8974L12.7969%2015.0367L14.7617%2013.4404L16.4104%2016.6269L16.5652%2017.7805L18.9869%2021.5713Z'%20fill='%23D97757'/%3e%3cpath%20d='M21.3629%2020.2507L21.4659%2020.8L21.1568%2021.2396L20.8476%2021.1297L19.0958%2019.8112L16.4165%2017.284L14.3555%2015.7457L14.9736%2013.6582L16.0041%2014.3175L16.6226%2015.5259L21.3629%2020.2507Z'%20fill='%23D97757'/%3e%3cpath%20d='M20.0232%2014.6482L22.5995%2014.8679L23.2178%2015.3074L23.6299%2015.9667V16.441L22.4964%2016.9556L16.7256%2015.4173L14.3555%2015.3074L14.9737%2013L16.6226%2014.3185L20.0232%2014.6482Z'%20fill='%23D97757'/%3e%3c/g%3e%3c/svg%3e)

In the long journey to make machines speak more like humans, we have focused on lexical accuracy, lifelike tone, and even vocal texture. Yet, we might have all overlooked a secret hidden between the lines. A secret that carries breath, emotion, and thought: the pause.
Today, we want to share a seemingly small but deeply human-centric advancement: We have enabled machines to understand human silence.
Where Does the "Mechanical Feel" of Machines Come From?
Imagine two versions of a voiceover:
- Version A: Flawless enunciation, delivered in one breath, information comes like rapid-fire, leaving not a single gap.
- Version B: It hesitates slightly at key moments, builds suspense before transitions; its rhythm itself tells you: "This is important," "Let's think," "The story is about to turn."
Which one moves you more? The answer is self-evident.
We are long accustomed to human speech not being a smooth line, but a mountainous soundscape with peaks, valleys, and breath. Those well-timed silences are the punctuation of speech, the carriers of emotion, and precious buffers for the listener's brain to digest information.
The "mechanical feel" of traditional machine voiceovers largely stems from this—they possess a good voice, but lack a heart that knows how to "breathe."
The "mechanical feel" of traditional machine voiceovers largely stems from this—they possess a good voice, but lack a heart that knows how to "breathe."
Beyond Punctuation: From "Grammar Rules" to the "Rhythm of Life"
An obvious idea might be: just have the machine follow punctuation rules. Pause longer for periods, shorter for commas.
But real-world speech is far more vibrant and complex than that.
- When excited, people might speak a whole passage in one breath, disregarding punctuation.
- When recalling or thinking, a pause might occur after any word, potentially where there is no comma.
- Different languages have inherent, different rhythms. The information load of ten Chinese characters might require a stream of swift Spanish notes to carry; while the rhythm of Japanese lies within the dense combination of Kana and particles.
Punctuation is merely the skeleton of text, while authentic pauses are the lifeblood flowing within the voice.
Our Answer: Replicating the "Breathprint" of Life
So, we changed our approach. We stopped commanding the machine to "guess based on rules," and instead guided it to "listen through data."
- Listening for Traces: We use Automatic Speech Recognition (ASR) technology. It not only outputs text but, more valuably, records the "birth" and "end" timestamps of each word on the timeline.
- Interpreting Silence: We examine the time intervals between words. Those unusually lengthened gaps are the genuine "breathing holes" left by the original speaker. This is not random emptiness; it is the prosody of language, the trace of thought.
- Cultural Adaptation: We calibrate the "sensitivity" of listening for different languages. For compact-rhythm languages like Chinese and Japanese, we capture more subtle pauses; for scriptio continua languages like Thai and Burmese, we use wider thresholds to perceive their more spacious rhythm.
In essence, we are translating the "life rhythm" of sound—those silences laden with hesitation, emphasis, recollection, and emotion—into labels that machines can understand, and then asking the TTS to reproduce it in audio.
A Simple Example to Feel the Weight of "Breath"
The original speaker might say:
"Our new model processes data in real time … (a natural inhalation and turn) … and delivers results within seconds."
A standard Text-to-Speech (TTS) would state it flatly:
"Our new model processes data in real time and delivers results within seconds."
After being "listened to" by our system, it generates:
"Our new model processes data in real time <break time="300ms"/>and delivers results within seconds."
"Our new model processes data in real time <break time="300ms"/>and delivers results within seconds."
These 300 milliseconds are not a cold algorithmic parameter. They are a moment of genuine silence "harvested" from the original audio, a thinking time the speaker left for you.
Why Insert Tags Instead of Stretching Audio?
Because we pursue "precision," not "homogenization." Like a skilled conductor who lifts the baton only at the end of a musical phrase, rather than slowing down the entire movement equally. Inserting
<break> tags allows us to:- Exercise Fine Control: Inject silence exactly where it's truly needed.
- Ensure Absolute Reliability: Guarantee each pause is within a reasonable range, avoiding unnatural long gaps.
- Maintain Broad Compatibility: Enable this understood "silence" to be accurately "performed" by major TTS engines.
Guarding This "Understanding," Preventing Misuse
Any sophisticated mechanism needs robust guardrails. Therefore, we have implemented multiple safeguards:
- Choosing Humility when Uncertain: If the speech recognition quality is poor, we prefer not to add any pauses rather than implant incorrect "breaths."
- Filtering False "Silence": Identify and ignore unnaturally long intervals caused by recognition errors.
- Protecting Output Purity: Cleanse any extraneous formats that might be accidentally added, ensuring the final instruction is clear.
- Quantifying "Naturalness": Standardize pause precision to 10ms, avoiding unnatural micro-jitters, making the rhythm smooth and stable.
Ultimately, What Difference Have We Achieved?
When machines learn silence, the change is subtle yet palpable.
- When telling a story, it gains a sense of suspense.
- When expressing an opinion, it gains a sense of power.
- When laying out descriptions, it gains a sense of imagery.
Users might not articulate the technical principles precisely, but their feedback points to the most essential feeling: "This voice sounds more real." "It doesn't feel rushed; it's comfortable."
This "naturalness" lies precisely within those perfectly replicated, seemingly insignificant silences.
An Analogy
If we compare a sentence to a path, with words as the paving stones, then the time between words is the spacing between the stones.
What we do is observe where the spacing has been naturally widened—those are the "breathing points" of the speaker's mind—and then, right there, we lay down a soft carpet of time (a
What we do is observe where the spacing has been naturally widened—those are the "breathing points" of the speaker's mind—and then, right there, we lay down a soft carpet of time (a
<break> tag), allowing the voice to pause and breathe there.The Road Ahead
This is just the beginning. In the future, we aspire for machines not only to replicate silence but to understand the emotion behind it—is it the hesitation of doubt, the solemnity after emphasis? The negative space before a transition, or the speechlessness of being moved?
We dream that it can intelligently adjust this "silence" based on the cultural rhythm of the target language, so that the translated voice is not only accurate in meaning but also harmonious in prosody.
Thus, what the machine produces is no longer just a correct sequence of words, but begins to possess the rhythm of life.
We have enabled machines to understand the unspoken parts of speech.
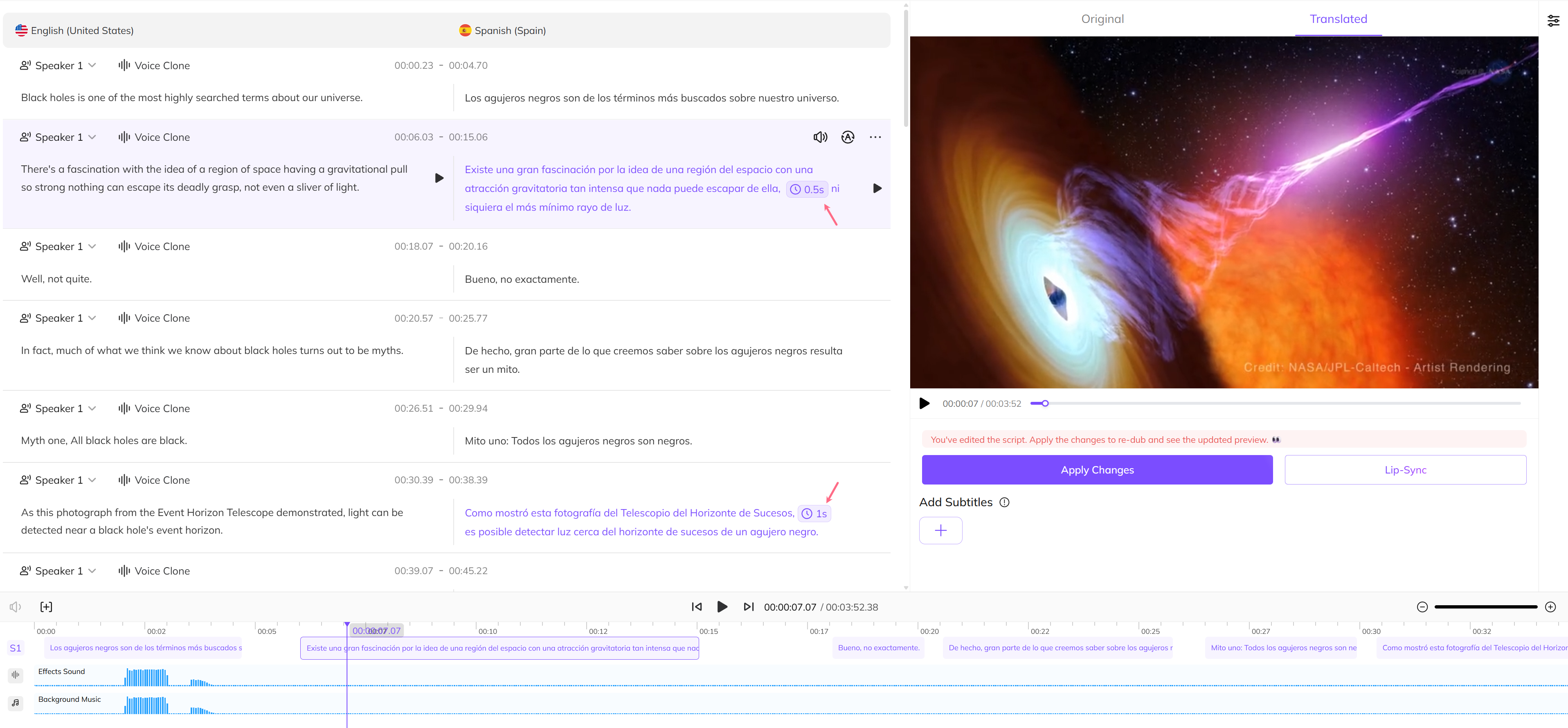
VMEG Video Translator
Discover how AI learns to perceive Silence in Speech through silent-speech-recognition and rhythm modeling. Training machines to capture human pauses, emotion, and breath.
Aubrey
We no longer let machines blindly guess where to pause. We taught them how to listen — to listen to the precious quiet between words in authentic human speech. Then, we carefully translate these silences, laden with breath and rhythm, into code and inject them into the synthesized voice.