如何将语音识别为文本
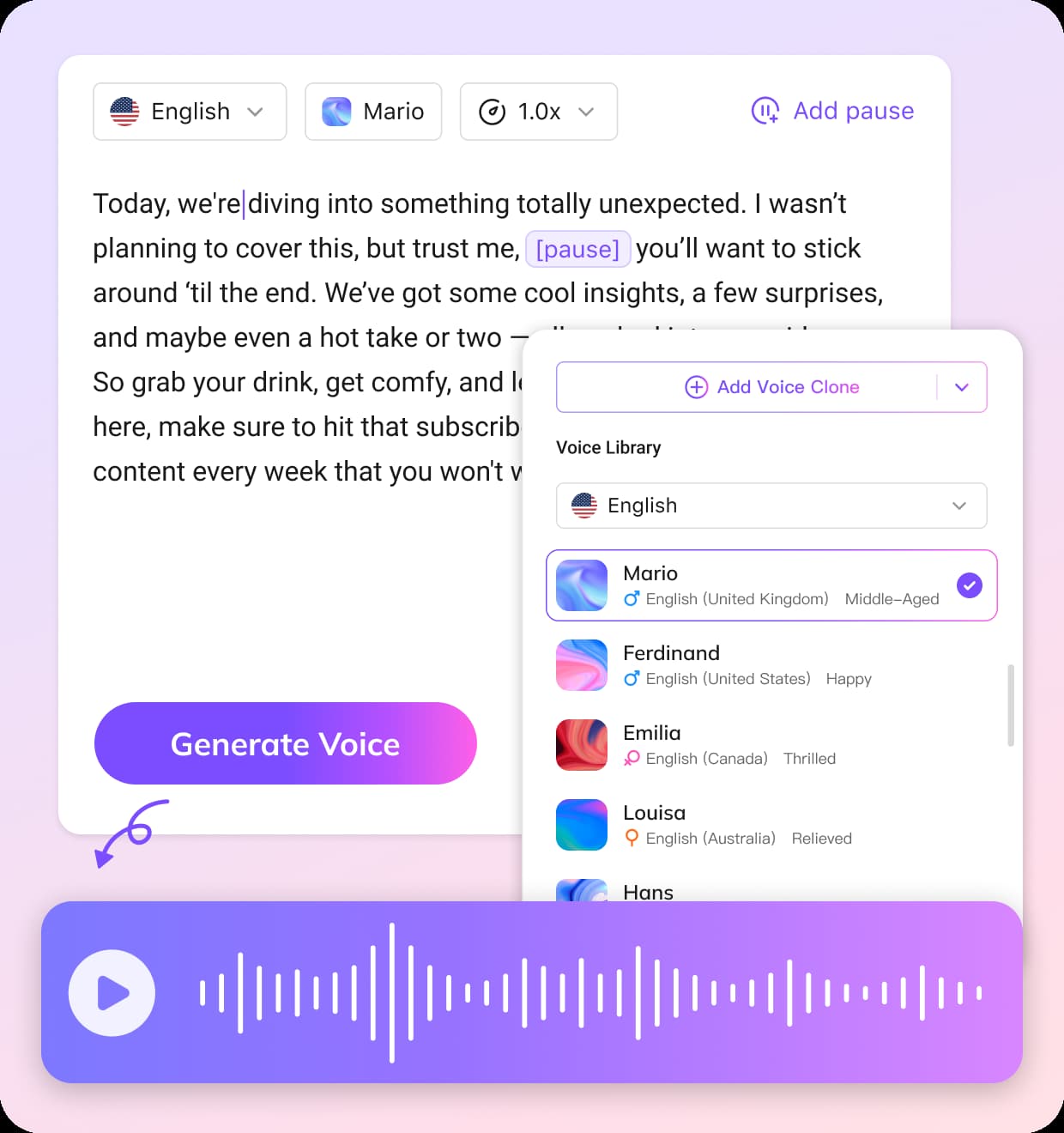
上传语音或音视频文件
点击上传按钮,将你的语音录音、采访、讲课或视频音轨导入工具。VMEG支持 MP3、M4A、AAC、WAV 等多种格式,并在上传后自动进入语音识别流程。
选择语言并设置识别模式
从列表中选择语音内容的语言,或开启自动语言识别功能处理混合语种。你还可以根据需求选择是否保留时间戳、是否自动段落化,或开启翻译模式生成双语文本。
校对文本并导出
生成的文字会显示在编辑器中,你可以根据需要进行校对、调格式或补充内容。完成后即可将文本导出为 TXT、DOCX 或 SRT,用于会议纪要、字幕整理、文稿撰写等场景。
为什么选择VMEG的语音识别工具

支持 170+ 种语言与多语言识别,轻松处理跨国语音
在跨国会议或访谈中,录音往往混杂多种语言,传统工具容易识别出错,导致整理难度倍增。VMEG 的语音识别模型能够自动分辨语种,即便夹杂方言或切换语言,也能保持稳定输出。这种多语言覆盖让用户无需再反复上传不同工具处理一次录音,真正节省大量时间,让整理工作更高效。
上传语音识别文字
高准确度语音识别,避免信息丢失,适用于会议与访谈
许多语音识别工具无法捕捉快速表达或嘈杂背景声中的细节,常出现漏词、断句混乱的问题。VMEG 通过语音特征深度分析,使会议纪要、访谈记录等长音频在嘈杂环境下也能保持高可读性。对内容创作者、研究人员或需要记录关键决策的团队来说,高准确度减少了人工校对成本,让原始信息得到最大程度保留。
上传语音识别文字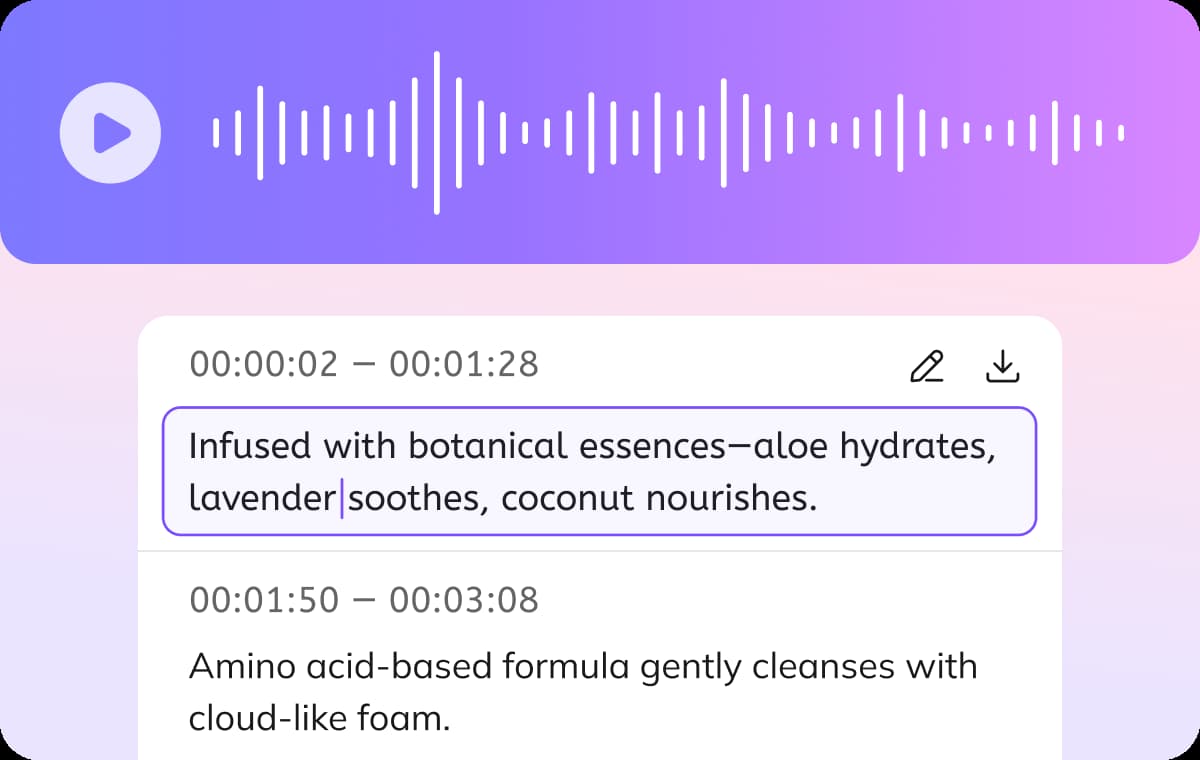
哪类人群会使用语音识别工具

播客和内容创作者
播客和内容创作者常用语音识别工具来快速整理访谈、解说或脚本,为剪辑与后期提供更高效的工作流程。录音内容被准确转写成文字后,他们能够更轻松地制作字幕、博客内容或多平台分发材料。

教育工作者、学生和语言学习者
教育工作者、学生和语言学习者使用语音识别工具来记录课堂、整理学习笔记或分析口语练习。将音频转为文字能帮助他们加深理解,也便于复习概念与查找重点。

销售、企业和机构
销售团队、企业和机构依靠语音识别工具来记录会议纪要、整理客户沟通内容并生成更清晰的业务文档。录音自动转写能减少手动记录时间,让团队将更多精力放在决策和执行上。
关于语音识别工具的常见问题解答
语音识别工具是一种将人类语音转换为可编辑文本的技术。它可识别多种语言和口音,用于会议记录、采访整理、视频字幕生成等场景。
准确率通常取决于录音质量、说话人清晰度、背景噪音以及语言模型。VMEG基于先进 AI 语音识别技术,甚至能在不那么清晰安静的环境音中,进行人声和背景音的分离,从而达到非常高的识别准确率。
是的,VMEG语音识别工具,支持识别170种语言,例如英语、中文、西班牙语、法语、阿拉伯语等,并可根据实际需求扩展。
不需要。AI 识别通常能在几秒到几分钟内完成,速度取决于文件大小和音频质量,比人工转录快几十倍。