

Dubbing Workflow: Built for Scale and Precision
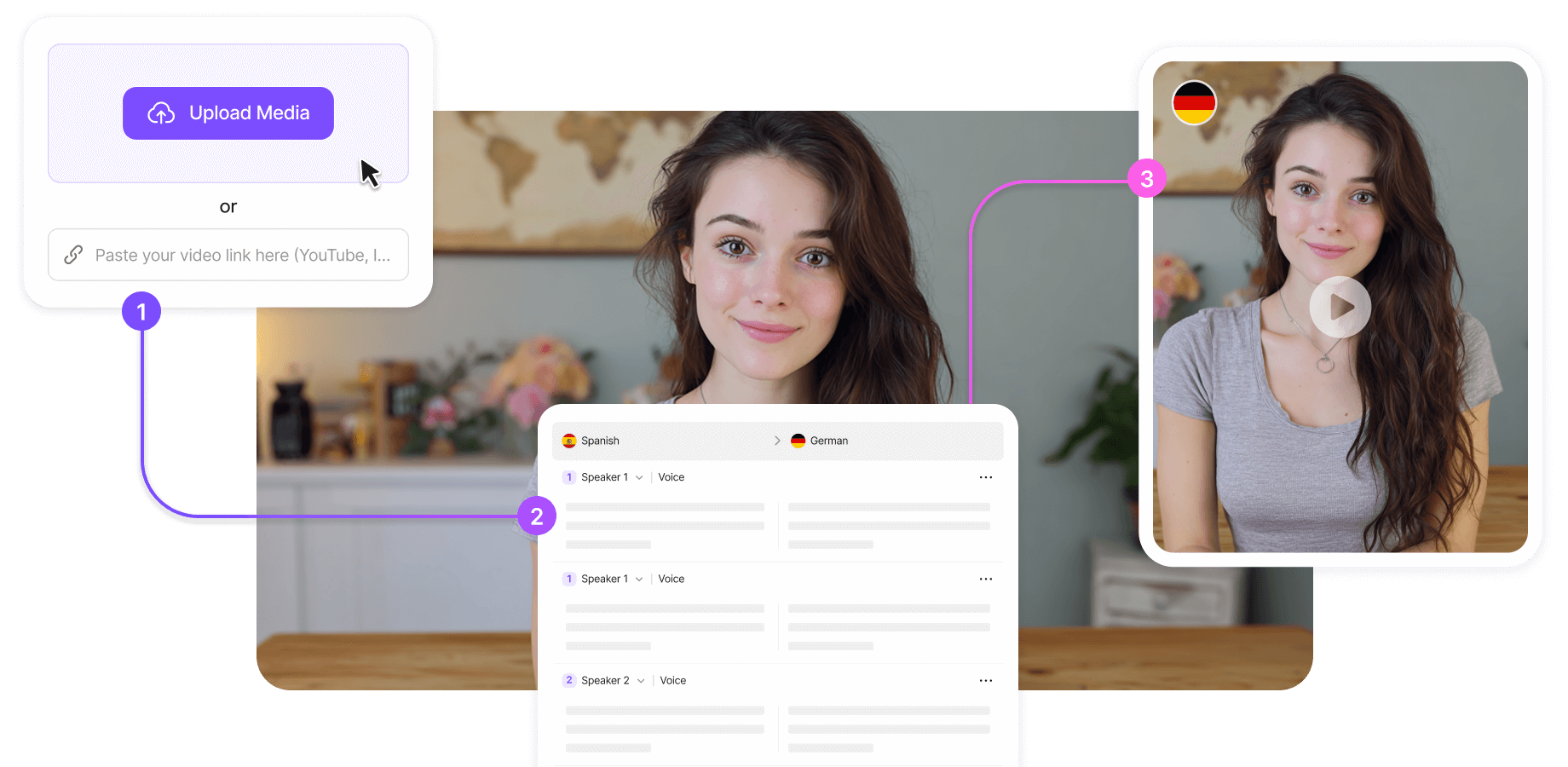
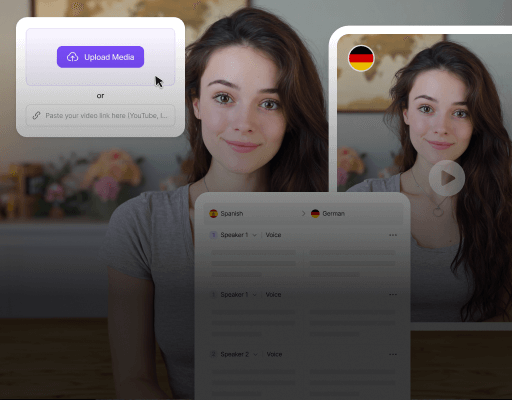
Upload Files & Create Your Resource Library
Easily upload and quickly kick off your localization process. Upload your original video files to the VMEG platform—we support multiple formats and sizes. Or use a URL link for instant uploads. Once uploaded, your files enter our automated processing pipeline immediately, ensuring your project launches efficiently.
Automatic Speech Recognition (ASR)
High-precision speech-to-text lays the foundation for localization. VMEG AI automatically identifies and transcribes spoken content in videos, rapidly converting raw audio into highly accurate text to provide reliable input for subsequent translation and dubbing workflows.

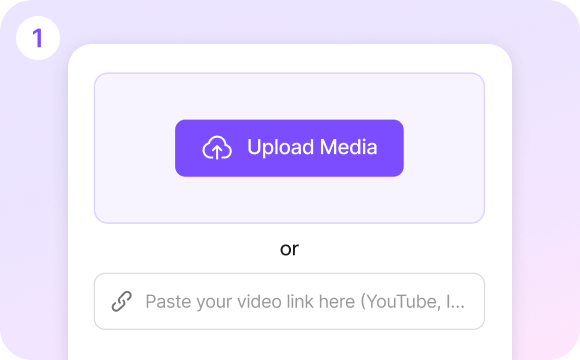
Translation & Text Validation
AI-generated translations with human proofreading and optimization support. VMEG automatically produces high-quality translated content using multilingual models. For projects demanding greater professionalism and brand consistency, human translation and proofreading can be incorporated to ensure precise accuracy in meaning, context, and terminology.
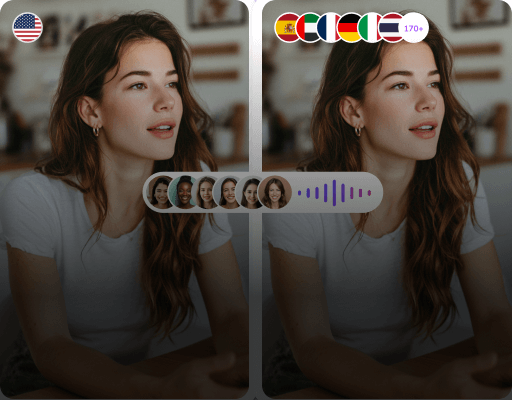
AI Voiceover Generation
Natural speech synthesis, restoring authentic expression. Generate voiceover tracks in the target language with a single click for confirmed translations. VMEG AI delivers smooth, natural speech with intonation and rhythm that closely match human speech, providing an immersive viewing experience for global audiences.
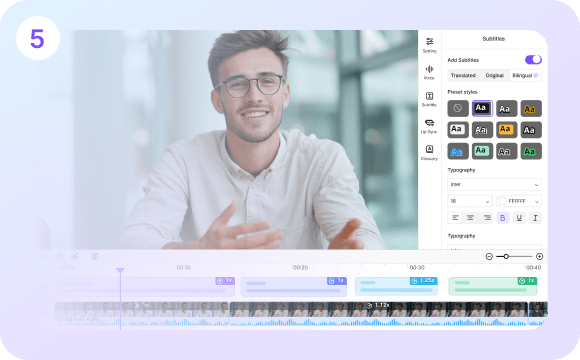
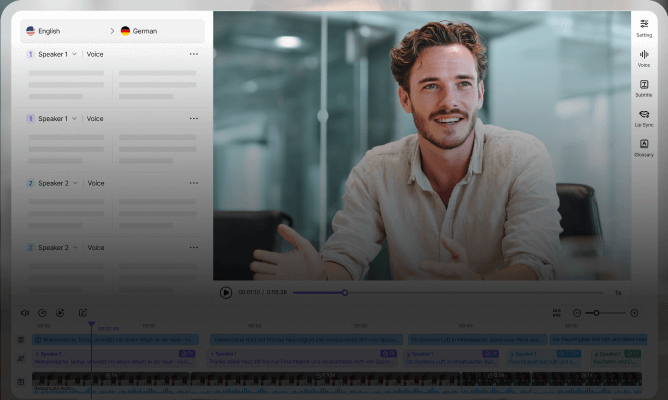
In-Platform Video Editing
Streamline editing on a unified platform to boost collaboration efficiency. Editors can complete subtitle synchronization, timeline adjustments, video editing, and style optimization directly within VMEG—eliminating frequent tool switching and enabling a truly integrated production workflow.
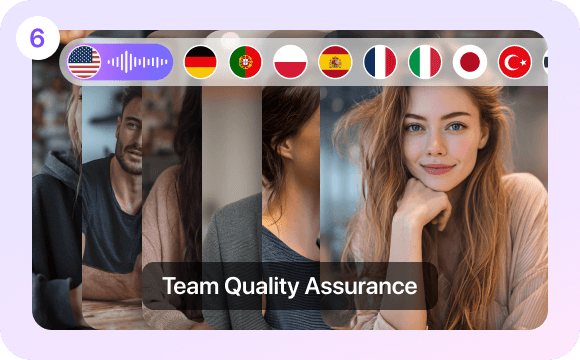
Team Quality Assurance (QA)
External quality control phase ensures final product excellence. Internal teams or external auditors conduct comprehensive reviews of translation accuracy, naturalness of voiceovers, and synchronization between visuals and subtitles to guarantee the final output meets professional and brand standards.
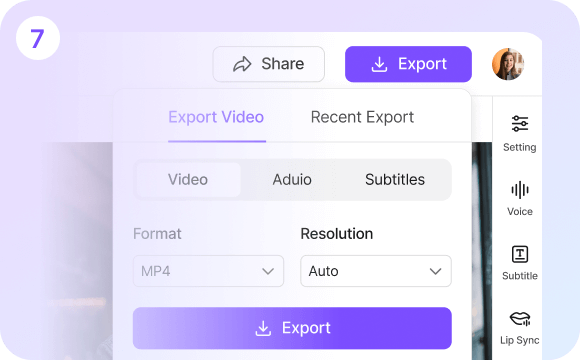
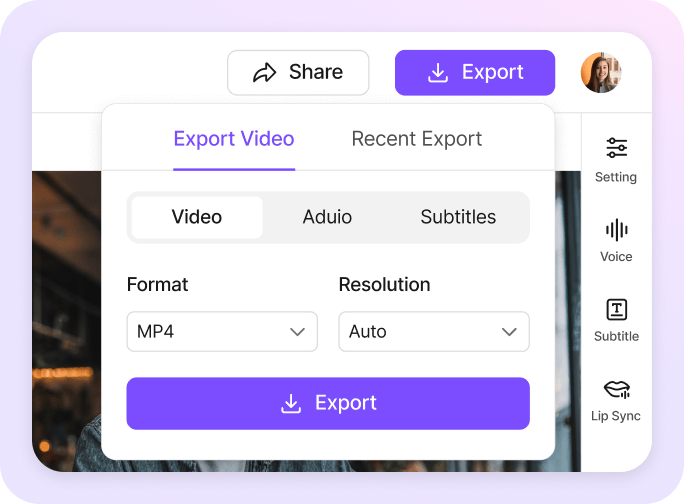
Export & Delivery
Efficient video export and rapid deployment. Use VMEG's one-click export to generate final videos, supporting multiple resolutions and formats for seamless adaptation to YouTube, TikTok, official websites, and enterprise-level publishing scenarios.
Professional Tools for Efficient Workflow
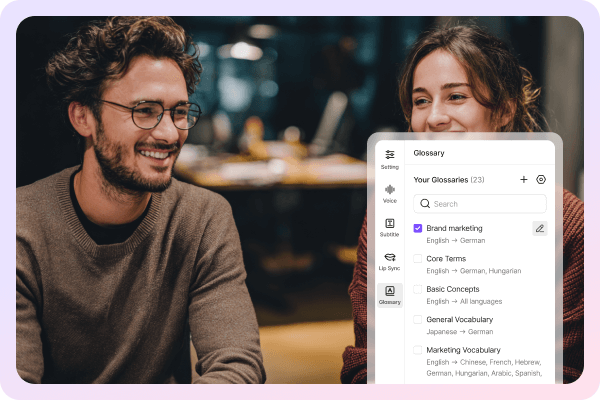
Glossary for Consistent Terminology
Batch processing capability is the primary threshold for enterprises evaluating video localization tools. VMEG supports one-click uploads of up to 20 tasks and can simultaneously process 20 languages, consolidating previously fragmented translation and production workflows into a single batch execution.
Whether expanding a single video into multiple language versions or synchronously launching multiple videos into the same language market, the system operates on batch video localization logic. This eliminates manual project splitting, significantly reducing operational and management costs.
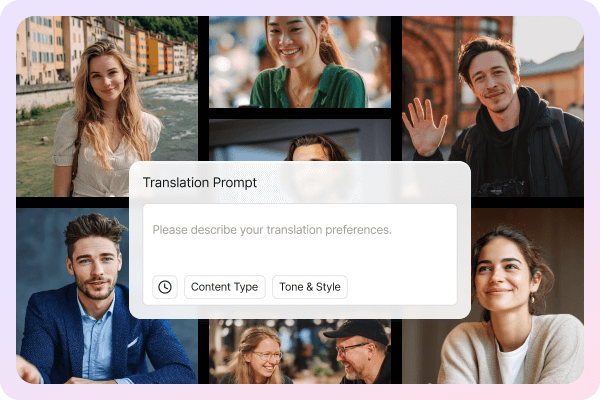
Translation Prompt for Accurate Localization
The Translation Prompt feature provides contextual descriptions for each video segment, helping the translation system understand industry terminology, tone, and target audience.
This is particularly crucial for professional video localization, ensuring consistency in accuracy and emotional expression across bulk video production while significantly reducing manual proofreading time.

Sentence-Level Emotion Control
VMEG supports single-sentence emotion control, ensuring translated speech retains the original speaker's emotional tone and intonation. Emotions like happiness, anger, sadness, calmness, and more are applied based on your input commands.
For production teams working on film/TV translations and anime dubbing, this ensures videos maintain their original emotional impact across multilingual versions, enhancing viewing experiences and information delivery.
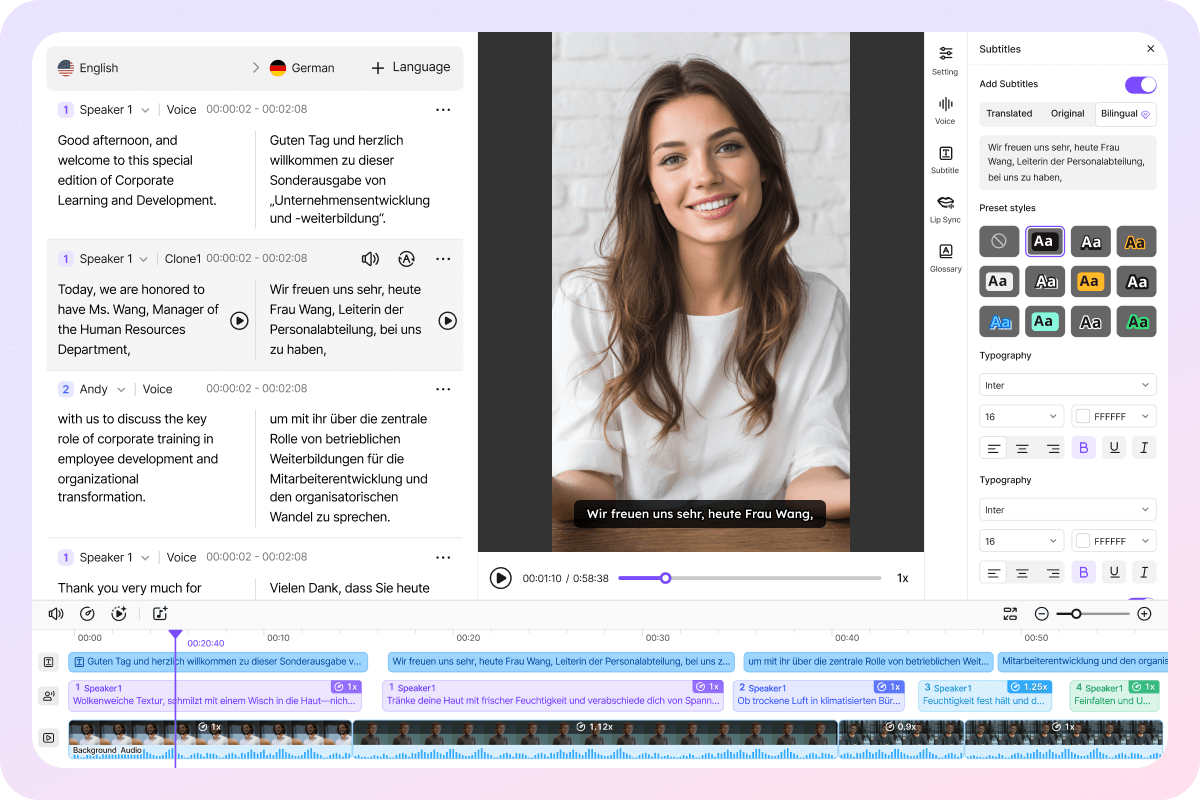
Absolute Control with our Glass Box Process
We believe in complete transparency throughout your project. VMEG uses an open process that gives your team the power to oversee every stage. You have the option to review the text after it is transcribed and translated but before the final dubbing is created.
This is a major advantage for high-stakes projects where every technical term must be exactly right. By having this oversight at the start, you can ensure your message is perfect in every language without needing to redo any work later.
Enterprise-Ready Video Localization Workflow
VMEG Professional Workflow combines automation with professional oversight, enabling scalable, multi-language video localization without sacrificing quality or control, unlike end-to-end black-box solutions.
| Feature | VMEG Professional Workflow | End-to-End Black Box |
|---|---|---|
| Workflow Transparency | Fully visible, step-by-step: transcription → contextual translation → dubbing → editing → review → export | Entire process opaque; limited visibility into what the AI did |
| Quality Consistency | Standardized process ensures uniform output across videos and languages | Output quality can fluctuate; results unpredictable |
| Context Awareness | Semantic understanding, tone preservation, multi-speaker recognition | Mostly literal translation; limited understanding of context |
| Professional Control | Editors can fine-tune scripts, subtitles, timing, voice style | Minimal control; adjustments are difficult post-process |
| Automation Stability | Automated but with checkpoints, recovery options, batch handling | Fully automated but fragile; errors propagate unnoticed |
| Scalability | Enterprise-ready; batch videos, multiple languages, voice cloning at scale | Limited batch support; scaling increases risk of errors |
| Turnaround Time | Fast and predictable; minutes per batch depending on size | Fast per video, but variable overall due to rework from errors |
How to Use VMEG Dubbing Workflow
Start Your Localization Project
Begin by creating a project and uploading your content library or pasting links. Unlike simple tools, VMEG Workflow is built for organization. You can assign specific target languages, upload custom glossaries, and set up your team’s workspace to handle multiple speakers and complex scripts right from the start.
Verify and Refine at Every Step
This is where the "Glass Box" approach shines. Instead of a black-box AI process, our workflow separates transcription, translation, and dubbing. You can pause at any stage to check for linguistic accuracy, modify technical terms, or adjust the translated text before a single word is dubbed, ensuring the foundation is 100% correct.
Collaborate and Export at Scale
Once the translation is approved, trigger the dubbing process across your chosen languages. Use the team dashboard to manage revisions and invite colleagues to review the output. When the project meets your standards, perform a batch export of high-quality localized videos, complete with synchronized audio and perfectly placed subtitles.
What people say about VMEG AI
"Human support that actually cares"
Support is fast and effective, but also human. The team really listens and keeps improving the platform.

"Surprisingly good Thai dubbing"
The program is easy to use. If you don't understand something, there are staff members who are willing to help quickly and willingly. In addition, the Thai voice dubbing is high quality and accurate
"Easy to use, even on day one"
I love VMEG.AI for its clean UI, which made my learning curve very comfortable and allowed my friends, who never worked with similar tools, to easily create a very solid video on their first try.
"Scale global creatives without freelancers"
VMEG helps this user translate ad creatives for a global audience without needing to hire freelancers. It keeps the same consistent, natural voice across languages, so their ads don't sound robotic or like a generic voice pack, and the setup was easy enough to start using it right away.
"Voices that sound like real people"
The most natural AI voice I've ever used. It doesn't just translate words, it delivers the nuance.
"Made for perfectionists and pros"
My go-to-tool for natural English–Italian video dubbing. Love the editing tool! As a perfectionist, I tweak until it's exactly what I envisioned and no credits are used in the process!
"Best video translator for Italian to Spanish"
The VMEG.AI video translator is the BEST I've ever tried for translating videos from Italian to Spanish. It even changed the voice in the two-way sections. And if the scene changes, it adjusted the length of the scenes as needed. Awesome! Impressive Voice Changes and Scene Timing
"Saves me hours on every video I localize"
It handles translation, subtitles, lip‑sync, voice cloning, and multi‑language output in one place, which makes video localization much more efficient and saves users significant editing time.
"Impressive dubbing for YouTube channels"
I have a YouTube channel with 127k subscribers. I needed to expand my audience to other areas. With VMEG, I achieved a fantastic result, and the dubbing is very natural. It's exactly what I was looking for.
"Best tools for dubbing videos"
Everything is great. Best tools to translate and dub videos. There is nothing I don't like about it. It's a very complete tool.
"A fast-acting team that takes feedback seriously"
When some features were missing at the beginning, the team moved fast to add what was needed and fix bugs, and they appreciate being able to regenerate multiple voice options until they find the one that fits best.
"Impressive Accuracy"
The accuracy of subtitles and timing is impressive, and voice cloning adds a professional touch that keeps the speaker's tone consistent. It saves me hours of manual editing and improves audience reach globally.

FAQs about VMEG AI Video Translation Workflow
What makes VMEG’s professional workflow suitable for enterprise video localization?
VMEG provides a structured, repeatable, and auditable workflow covering ASR, translation, voiceover, editing, and export. This eliminates fragmented tools and manual handoffs, enabling enterprises to scale multilingual video production with predictable quality.
Can VMEG handle large-scale batch video localization projects?
Yes. VMEG supports batch uploads of up to 20 tasks per job and simultaneous processing into 20 languages, making it ideal for enterprises expanding content across multiple markets or launching multilingual campaigns at once.
How does VMEG ensure translation accuracy for professional content?
VMEG combines AI-powered translation with optional human proofreading, glossary enforcement, and contextual translation prompts—ensuring accuracy in terminology, tone, and domain-specific language.
Can teams review and edit translations directly on the platform?
Yes. VMEG includes an in-platform editing studio where teams can adjust subtitles, fine-tune translations, sync timelines, and preview results—without switching between external tools.
How does VMEG maintain consistency across multilingual video versions?
Using custom glossaries, translation prompts, and style guidance, VMEG ensures consistent terminology, tone, and messaging across all translated videos, even at large scale.
Related Articles
Dive into expert articles from the VMEG team covering AI technology, language research, and real-world localization insights


Why VMEG is Trustworthy

Privacy-First by Design
VMEG is built on a privacy-first architecture. Your videos, voice samples, and scripts are encrypted, isolated, and never used to train AI models by default. You stay in full control of your data—always.

Enterprise-Grade Data Protection
VMEG is architected with enterprise security at its core. All customer data is encrypted using AES-256 at rest and TLS 1.3 in transit, ensuring sensitive media assets remain protected throughout the entire processing lifecycle.

Strict Data Isolation & Ownership
Customer data is fully isolated by workspace. VMEG does not access, reuse, or train on your proprietary videos, voice data, or scripts by default. You retain full ownership and intellectual property rights over all inputs and outputs.

Infrastructure Built for Scale & Compliance
Running on secure AWS infrastructure, VMEG delivers high availability, redundancy, and global scalability. VMEG is designed to support enterprise localization workflows while aligning with modern security and compliance standards.
















Professional AI and Human-in-the-loop Workflow
VMEG’s professional workflow streamlines video localization from transcription to translation and delivery. Built for teams managing multilingual content at scale.