


'%3e%3cpath%20d='M21.0949%203.79395L13.9961%209.82854H21.0949V3.79395Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M13.998%209.82854L7.44531%203.79395V9.82854H13.998Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M13.9961%202.69922V25.1919'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M20.5488%2016.4113L13.9961%209.82812V18.2217L20.5488%2024.0918V16.4113Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M7.44531%2016.4113L13.998%209.82812V18.0526L7.44531%2024.0918V16.4113Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M4.71094%209.82812V18.6057H7.44125V16.4113L13.9941%209.82812H4.71094Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3cpath%20d='M13.9961%209.82812L20.5488%2016.4113V18.6057H23.2792V9.82812H13.9961Z'%20stroke='black'%20stroke-width='1.38'%20stroke-miterlimit='10'/%3e%3c/g%3e%3c/svg%3e)

'%3e%3cmask%20id='mask0_21456_29260'%20style='mask-type:luminance'%20maskUnits='userSpaceOnUse'%20x='0'%20y='0'%20width='28'%20height='28'%3e%3cpath%20d='M27.5%200.5H0.5V27.5H27.5V0.5Z'%20fill='white'/%3e%3c/mask%3e%3cg%20mask='url(%23mask0_21456_29260)'%3e%3cpath%20d='M14%2027.5C13.4854%2024.1035%2011.8974%2020.9608%209.46828%2018.5317C7.03922%2016.1026%203.89651%2014.5146%200.5%2014C3.89651%2013.4854%207.03922%2011.8974%209.46828%209.46828C11.8974%207.03922%2013.4854%203.89651%2014%200.5C14.5147%203.89644%2016.1028%207.03905%2018.5318%209.46816C20.9609%2011.8972%2024.1035%2013.4853%2027.5%2014C24.1035%2014.5147%2020.9609%2016.1028%2018.5318%2018.5318C16.1028%2020.9609%2014.5147%2024.1035%2014%2027.5Z'%20fill='url(%23paint0_linear_21456_29260)'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_21456_29260'%20x1='9.5'%20y1='9.5'%20x2='20.75'%20y2='21.875'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23F0DCD6'/%3e%3cstop%20offset='0.914506'%20stop-color='%231D6DFF'/%3e%3c/linearGradient%3e%3cclipPath%20id='clip0_21456_29260'%3e%3crect%20width='28'%20height='28'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M22.8019%2011.2412L23.5234%2011.6807V12.0103L23.3172%2012.7796L14.5579%2014.9771L13.7344%2012.7951L22.8019%2011.2412Z'%20fill='%23D97757'/%3e%3cpath%20d='M19.5236%204.77832L20.5322%205.00396L20.8%205.35575L21.0552%206.19876L20.9494%206.73644L15.0712%2015.3068L13.1133%2013.2191L18.5338%205.63471L19.5236%204.77832Z'%20fill='%23D97757'/%3e%3cpath%20d='M14.4577%203.43951L15.0761%203L15.5912%203.21976L16.1065%203.9889L14.6949%2013.0345L13.7364%2012.3397L13.3242%2011.131L14.0456%204.31853L14.4577%203.43951Z'%20fill='%23D97757'/%3e%3cpath%20d='M7.84766%203.5851L8.48285%202.7199L8.89716%202.61914L9.71923%202.74717L10.125%203.08581L13.0815%2010.0748L14.1509%2013.3954L12.8997%2014.1372L8.13117%204.91019L7.84766%203.5851Z'%20fill='%23D97757'/%3e%3cpath%20d='M4.77232%208.38688L4.56641%207.50742L5.18478%206.73828L5.90613%206.84816H6.11223L10.4403%2010.2544L11.78%2011.3531L13.6349%2012.8914L12.6044%2014.7594L11.6769%2013.9903L11.0586%2013.331L5.08168%208.82593L4.77232%208.38688Z'%20fill='%23D97757'/%3e%3cpath%20d='M3.53288%2014.0982L3.06641%2013.5489L3.06647%2013.0601L3.53288%2012.8896L8.78833%2013.2193L13.9408%2013.6588L13.7736%2014.7528L3.94502%2014.2082L3.53288%2014.0982Z'%20fill='%23D97757'/%3e%3cpath%20d='M6.62378%2019.8178H5.59334L5.18359%2019.3146V18.7132L6.93299%2017.3946L14.045%2012.5674L14.7648%2013.8785L6.62378%2019.8178Z'%20fill='%23D97757'/%3e%3cpath%20d='M8.57739%2022.8884L8.16518%2022.9984L7.54688%2022.6687L7.64995%2022.1193L13.7299%2013.5488L14.5543%2014.7574L10.0201%2021.1305L8.57739%2022.8884Z'%20fill='%23D97757'/%3e%3cpath%20d='M13.7361%2023.9861L13.4271%2024.4257L12.8088%2024.6454L12.2935%2024.2058L11.9844%2023.5466L13.5301%2014.6465L14.4576%2014.7563L13.7361%2023.9861Z'%20fill='%23D97757'/%3e%3cpath%20d='M18.9869%2021.5713V22.4503L18.8838%2022.7799L18.4716%2022.9997L17.7503%2022.8974L12.7969%2015.0367L14.7617%2013.4404L16.4104%2016.6269L16.5652%2017.7805L18.9869%2021.5713Z'%20fill='%23D97757'/%3e%3cpath%20d='M21.3629%2020.2507L21.4659%2020.8L21.1568%2021.2396L20.8476%2021.1297L19.0958%2019.8112L16.4165%2017.284L14.3555%2015.7457L14.9736%2013.6582L16.0041%2014.3175L16.6226%2015.5259L21.3629%2020.2507Z'%20fill='%23D97757'/%3e%3cpath%20d='M20.0232%2014.6482L22.5995%2014.8679L23.2178%2015.3074L23.6299%2015.9667V16.441L22.4964%2016.9556L16.7256%2015.4173L14.3555%2015.3074L14.9737%2013L16.6226%2014.3185L20.0232%2014.6482Z'%20fill='%23D97757'/%3e%3c/g%3e%3c/svg%3e)
Key Takeaways
- An AI agent architecture is an important factor in designing an AI agent, as it determines its process and output. There are various types of AI agent architectures, and the choice may depend on the system's design and purpose.
- Video localization requires an AI agent architecture to streamline the workflow. It also provides a range of benefits, including automated task execution, parallel processing, intelligent coordination, scalability, and continuous improvement.
- The AI agent architecture patterns for video localization vary. Some of the types of AI agent architectures are reactive, deliberative, hybrid, single-agent, multi-agent, hierarchical, and workflow-orchestrated architectures.
- Several factors must be considered when choosing the right AI agent architecture, such as evaluating task complexity, determining the required autonomy level, and considering budget and performance constraints.
- VMEG AI is one of the best tools for video localization and its architecture is thoughtfully designed for effective global localization.
Maybe you have already seen an AI agent in a tool or platform you use. This AI agent improves how things work and helps users do things more conveniently. Behind every AI agent is an architecture that defines its workflow. It helps the AI agent perceive, plan, and act accordingly to achieve an output.
AI agents are one of the technological trends that developers design to make things easier for their users. Various AI agents can be designed for specific purposes. Gartner (2025) predicts that in GenAI’s future, AI agents will increase in number and collaborate.
There will be more AI agents, as they will make the workflow faster and easier and provide various benefits, such as saving time and reducing costs. In this post, we will discuss AI agent architecture in video localization.
What Is AI Agent Architecture?
An AI agent architecture is a system design that defines an AI agent’s workflow. It plays an important role in determining how an AI agent will perform the task and deliver a quality output. In video localization, a system can have a single or multiple layers of architecture to produce high-quality videos.
An AI agent architecture is the design that structures the AI Agent workflow. It defines how an AI agent will perceive data, create a plan, make decisions, and take actions to achieve the goal. The architecture is like a blueprint on how an AI agent thinks and acts to produce an output. It determines how each step and task are organized internally.
Why Video Localization Requires an AI Agent Architecture
Video localization is the process of translating and adapting video content for different languages. It includes transcription, translation, subtitle synchronization, voice adaptation, dubbing, lip-sync, and quality checking. These tasks are complex, which is why using an AI agent architecture is helpful, as it automates and coordinates the workflow.
Traditional Localization Workflow
A traditional localization workflow involves manual processes and multiple professionals, which can make it more accurate but also take longer and cost more.
It typically includes:
- Transcription. Converting speech into text.
- Translation. Translating the transcript, file, or media into the target language.
- Subtitle creation. Formatting translated text into subtitles.
- Dubbing. Dubbing the audio into the target language.
- Timing and synchronization. Aligning subtitles with video scenes.
- Quality review. Human editors check grammar, cultural accuracy, and context.
Challenges Without AI Agents
Without AI Agents, video localization can be challenging due to the various tasks and processes involved. Here are some challenges in video localization if there are no AI agents:
- Slow processing. Some steps may need to be completed before the next one, creating bottlenecks.
- High costs. Manual video localization can be costly, as it requires significant human labor, from translation to editing.
- Limited scalability. It will be difficult to localize content into many languages, especially if the workflow relies on manual effort, so the video that can be localized will also be limited. It will also be challenging to adapt to trends and expand to new markets quickly.
- Inconsistent quality. Another challenge is quality, especially when multiple translators and editors are involved, as interpretation may differ, leading to inconsistencies.
- Difficult workflow coordination. Managing multiple tasks, such as transcription, translation, timing, dubbing, and quality control, can become complex without automated coordination.
How AI Agent Architecture Solve These Problems
AI agents can solve the challenges above because the architecture on which they are designed enables automated, intelligent coordination of localization tasks.
Key benefits:
- Automated task execution. AI agents can automatically perform tasks such as translation, speech recognition, and subtitle generation, speeding up the process and enabling you to localize many videos in just a few minutes.
- Parallel processing. The AI agent architecture enables a system to handle multiple tasks, thereby accelerating localization.
- Intelligent coordination. The components and other elements in the workflow coordinate intelligently, ensuring that each step receives the correct inputs and produces consistent, high-quality outputs.
- Scalability. AI-driven systems can localize videos into many languages with minimal effort. With AI agents, you can be more productive and focus more on important tasks.
- Continuous improvement. Learning-based agents can continuously improve translation accuracy and other key metrics by learning from past interactions and reviewing their output.
Core Components of AI Agent Architecture for Video Localization
Video Perception Layer
This layer understands the video and its content. It uses computer vision to analyze frames and detect objects, scenes, facial expressions, and on-screen text. It can also identify context, such as location, actions, and scene transitions. By extracting structured visual information, the system can align visual cues with dialogue and narration, which is essential for accurate localization.
Language Processing Layer
The language processing layer interprets and translates the spoken and written language in the video. It processes transcripts generated from speech recognition and applies natural language understanding to maintain and capture the meaning, tone, and context. It handles tasks such as translation, summarization, sentiment analysis, and intent detection.
Audio Generation Layer
The audio generation layer produces localized voice tracks that match the translated script. Voice cloning systems and text-to-speech technologies are used to generate speech that aligns with the original speaker's timing, emotion, and style. It can also adjust voice characteristics, such as pitch, pacing, and accent, to make it sound more natural.
Subtitle & Metadata Layer
The subtitle and metadata layer manage the creation and formatting of subtitles and additional localization data. It ensures that subtitles are synchronized with the audio and displayed in a readable format, in accordance with regional standards. Proper subtitle and metadata management improves both accessibility and discoverability of localized video content.
Workflow Orchestration Layer
This layer coordinates all other components in the AI localization process. It manages task scheduling, data flow between models, and sequencing of processes such as transcription, translation, voice generation, and subtitle creation. To ensure that the final output meets the localization goal, it also includes monitoring, error handling, and quality control mechanisms. An orchestrated workflow enables scalable and automated video localization across multiple languages and platforms.
AI Agent Architecture Patterns for Video Localization
In video localization, AI agents transcribe, translate, and format content accurately across different languages and contexts. The architecture of these agents directly affects efficiency, scalability, and accuracy. The architecture may vary depending on how the AI agent is designed. The following patterns describe how AI agents can be designed, deployed, and coordinated in video localization systems.
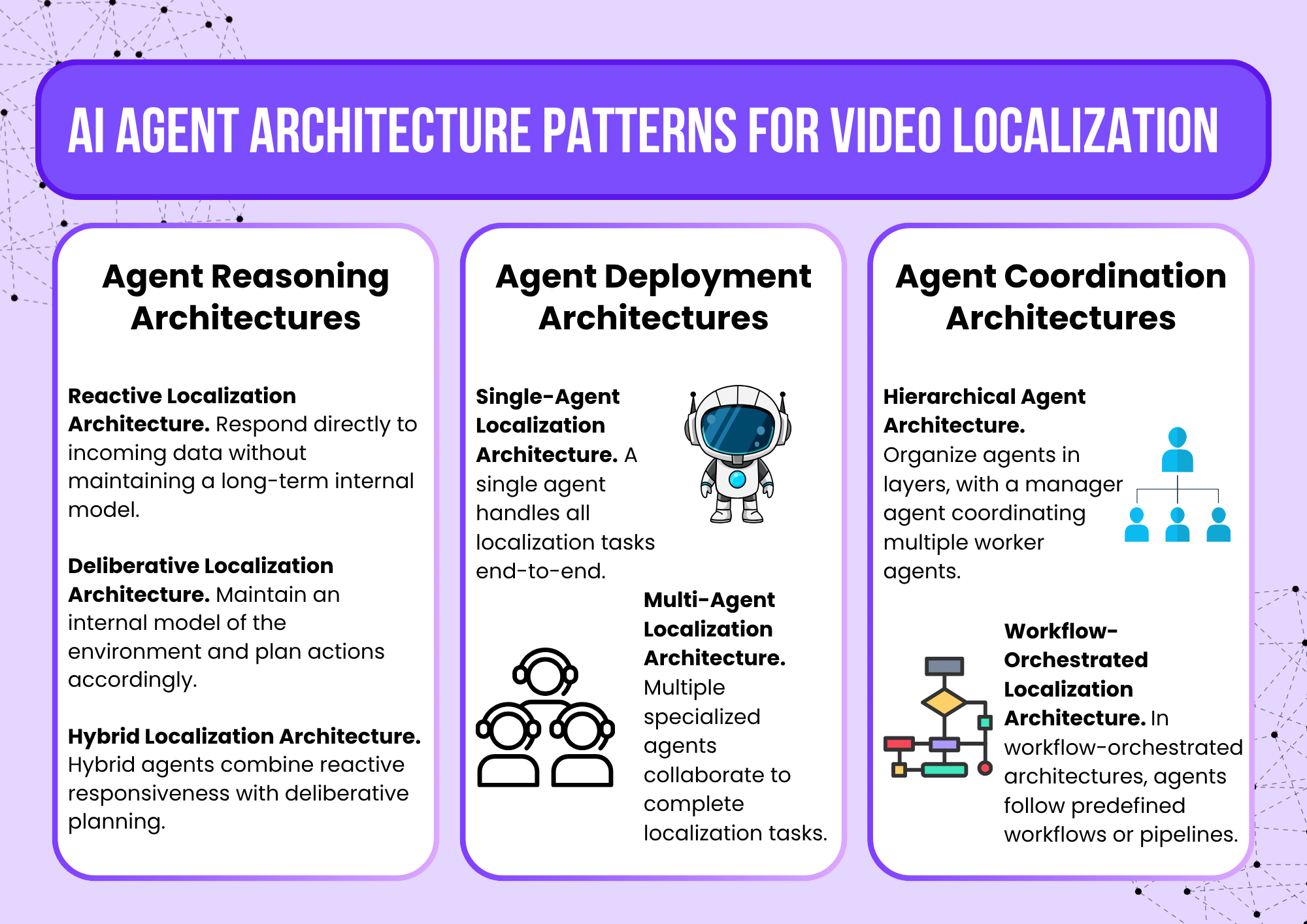
Agent Reasoning Architectures
Agent reasoning architectures define how an AI agent processes inputs and makes decisions. When it comes to video localization, it determines how the agent can handle tasks such as transcription, translation, and subtitle timing quickly and intelligently.
Reactive Localization Architecture
Reactive agents respond directly to incoming data without maintaining a long-term internal model.
- Example: Immediately adjusting subtitle timing when a speech segment is detected.
- Advantages: Fast and lightweight.
Deliberative Localization Architecture
Deliberative agents maintain an internal model of the environment and plan actions accordingly. These agents plan localization tasks based on project requirements.
- Example: Planning subtitle translation for a full video segment before applying changes.
- Advantages: More accurate and context-aware; capable of complex multi-step reasoning.
Hybrid Localization Architecture
Hybrid agents combine reactive responsiveness with deliberative planning.
- Example: Using reactive adjustments for immediate timing corrections while planning translations across scenes.
- Advantages: Balances speed and intelligence; widely used in modern video localization pipelines.
Agent Deployment Architectures
Agent deployment architectures define how many agents are used and how responsibilities are distributed across the system. These architectures affect scalability, fault tolerance, and maintainability.
Single-Agent Localization Architecture
A single agent handles all localization tasks end-to-end.
- Example: One AI agent transcribes, translates, and formats subtitles for a video.
- Advantages: Simple to implement and maintain.
- Limitations: Limited scalability; performance may drop with long videos or high workloads.
Multi-Agent Localization Architecture
Multiple specialized agents collaborate to complete localization tasks.
- Example: One agent handles transcription, another handles translation, and a third formats subtitles.
- Advantages: Scalable, modular, and easier to optimize for large video volumes.
- Limitations: Requires communication protocols and agent orchestration.
Agent Coordination Architectures
Agent coordination architectures define how multiple agents interact and synchronize tasks. It is important in complex localization pipelines involving multiple AI agents.
Hierarchical Agent Architecture
Hierarchical architectures organize agents in layers, with a manager agent coordinating multiple worker agents.
- Example: A manager agent assigns segments to transcription, translation, and subtitle agents, ensuring consistency and efficiency.
- Advantages: Clear task delegation, efficient handling of complex pipelines, and easy monitoring.
- Limitations: Slightly more complex to design; potential bottleneck at the manager agent.
Workflow-Orchestrated Localization Architecture
In workflow-orchestrated architectures, agents follow predefined workflows or pipelines.
- Example: After the video is uploaded, there is a predefined workflow for agents and tasks, from Speech Recognition Agent, Translation Agent, and Subtitle Formatting Agent to Quality Check Agent.
- Advantages: Structured, predictable, and easier to integrate into enterprise video platforms.
- Limitations: Less flexible; may struggle with unexpected input or dynamic changes.
Example of AI Agent Architecture for Video Localization: VMEG AI
VMEG AI’s Localization Agent leverages a modern AI system that employs hybrid reasoning, multi-agent deployment, and workflow coordination to handle complex video localization tasks. Its architecture enables scalable, accurate, and efficient localization of global video content.
Core Architecture Layers in VMEG AI
The reasoning architecture layer of VMEG AI combines reactive, deliberative, and hybrid reasoning to handle all stages of video localization. This layered reasoning enables VMEG AI to efficiently process complex, multilingual videos, adapting to dynamic workflow events without reprocessing everything.
Agent Reasoning Layer
- Reactive behavior. The agent responds immediately to workflow events, such as subtitle misalignment, audio anomalies, or user credits.
- Deliberative planning. Before processing content, the agent analyzes the video, identifies transcription, translation, dubbing, and subtitling requirements, and prepares a multi-step localization plan. This allows it to maintain context and make intelligent, goal-oriented decisions.
- Hybrid execution. Integrates reactive adjustments with deliberative planning. The agent follows the planned workflow while dynamically adjusting to workflow events or unexpected variations, balancing speed, accuracy, and flexibility.
Agent Deployment Layer
VMEG AI’s deployment architecture organizes the system into a logical single-agent interface with modular internal modules. Its deployment design ensures scalability while maintaining a clear, user-friendly interface.
- Single-agent interface. Users interact with one cohesive agent, simplifying the experience.
- Internal modular agents. Specialized modules handle transcription, translation, subtitle timing, voice selection, and quality assurance. Each module can react to workflow events independently, allowing local corrections without affecting unrelated modules.
- Parallelized execution. Modules can operate concurrently on different segments of a video or multiple videos simultaneously, improving efficiency.
Agent Coordination Layer
VMEG AI coordinates multiple modules using a hybrid hierarchical and workflow-orchestrated approach. This coordination layer ensures complex workflows are executed efficiently and produce consistent output across multiple videos and languages.
- Hierarchical coordination. A manager module oversees all sub-tasks, delegating work to specialized modules and monitoring progress.
- Workflow orchestration. Tasks follow a structured pipeline or workflow.
It follows a workflow, from transcription, translation, and subtitle timing to quality assurance and export.
Each module reacts to events (like edits or misalignments) while maintaining alignment with the overall workflow.
- Human-in-the-loop checkpoints. Users review and approve the agent’s plan before final execution, adding flexibility, quality control, and error mitigation.
Why This Architecture Scales for Global Video Localization
VMEG AI’s architecture is effective for global localization, as it combines intelligent reasoning, modular deployment, and structured coordination. These features make VMEG AI a robust, scalable, and flexible solution for localizing videos across regions, languages, and formats.
- Event-driven adaptability. Reactive adjustments allow the system to respond to dynamic workflow events while maintaining plan integrity.
- Parallelized multi-step processing. Modular internal agents can handle transcription, translation, and subtitling concurrently, speeding up large-scale projects.
- Workflow orchestration with human oversight. Structured pipelines and review checkpoints ensure consistent, high-quality output at scale.
- Extensible modular design. New languages, audio formats, or subtitle styles can be added without redesigning the system, supporting global expansion and future-proofing.
Challenges in AI Agent Architecture for Localization
Designing an AI agent architecture for localization poses challenges, as it involves balancing speed, accuracy, scalability, and flexibility.
- Balancing Reactive and Deliberative Reasoning
Reactive reasoning allows agents to respond quickly to workflow events, but excessive reliance can reduce accuracy, while overly deliberative planning may slow down the process. Poor balance can lead to delays in localization or inconsistent outputs, especially for long or complex videos or content.
- Multi-Agent Coordination Complexity
When multiple internal agents or modules are deployed, ensuring smooth coordination becomes difficult. Agents must synchronize outputs, share context, and handle conflicts. Misalignment between transcription, translation, and subtitling agents can result in errors or duplicated work.
- Scalability Across Languages and Formats
Supporting hundreds of languages, dialects, and video formats requires a modular yet extensible architecture. Without proper modularity and parallelization, the system can become a bottleneck for global-scale localization projects.
- Error Handling and Quality Assurance
Errors in transcription, translation, or subtitle alignment are inevitable. The AI agent architecture system must detect, correct, and prevent cascading errors across the workflow. Failures in error handling can reduce trust in the system and increase the need for human intervention.
- Human-in-the-Loop Integration
Incorporating human review points without slowing the workflow or breaking automation is difficult. Over-reliance on humans might reduce system efficiency, while under-reliance risks quality loss.
Future of AI Agent Architecture in Video Localization
The AI agent architecture for video localization must evolve to become more intelligent, adaptive, and scalable.
Autonomous Media Production Pipelines
The localization workflow will continue to improve, and developers will update it to make it more useful. Workflows will be more autonomous and will produce higher-quality output. It can reduce human intervention and accelerate global-scale localization.
Multi-Agent Creative Collaboration
According to Fortune Business Insights (2026), the growth of multi-agent architectures is one of the trends in AI agents. These agents work in coordination to execute complicated tasks within enterprise systems.
Future architectures will deploy distributed, coordinated agents, each specialized in tasks such as transcription, translation, voice adaptation, or quality control. Coordination layers will enable agents to communicate, share context, and resolve conflicts, ensuring accurate, consistent output across large volumes of video. It will support scalable and modular deployment for enterprise-level workflows.
Real-Time and Event-Driven Localization
AI agents will handle near real-time localization, reacting to dynamic events in live or pre-recorded workflows. This trend highlights the importance of hybrid reasoning and workflow orchestration for speed and accuracy.
AI-Powered Global Content Distribution
Localized videos will be automatically formatted and optimized for multiple languages. It will ensure that languages, formats, and cultural nuances are precise. Scalable deployment architectures will ensure parallel processing of large content volumes, maintaining high quality and consistency. It will help the system handle complex, global distribution efficiently.
Integration of Generative AI and LLMs
Large Language Models and generative AI will improve translation accuracy, tone preservation, and context-aware subtitling. Agents will use these models to summarize, adapt, or personalize content for specific audiences while maintaining high localization quality.
How to Choose the Right AI Agent Architecture
Choosing the right AI agent architecture for video localization requires carefully balancing task requirements, environment constraints, autonomy, scalability, and resource limitations.
Evaluate Task Complexity
Evaluate the task's complexity to determine whether the AI agent architecture can handle it efficiently. Check the tasks, such as transcription, translation, lip-sync, subtitling, and dubbing.
Determine Required Autonomy Level
Decide the level of autonomy that the agent needs, such as fully automated, human-in-the-loop, or collaborative. Single-agent architectures are suitable for straightforward, end-to-end localization tasks. Multi-agent architectures are better for distributed, complex workflows involving multiple languages, content types, or quality assurance steps.
Budget & Performance Constraints
Another important factor to consider is the budget and performance constraints. Check the resources, latency requirements, and ongoing costs to determine whether it is within your budget and whether the AI agent’s architecture can perform well. Choose an AI Agent Architecture that balances cost and quality and produces high-quality output.
FAQs
What is AI Agent Architecture?
An AI agent architecture is a structure that an AI Agent uses to perform tasks and achieve its goal.
What is an example of an AI Agent Architecture in video localizaton?
The AI agent architecture varies depending on the video localization tool. For example, a video localization AI agent’s architecture may comprise multiple layers, such as reactive, deliberative, and hybrid localization architectures.
What are the components of AI Agent Architecture?
The components of an AI agent's architecture depend on the system's purpose. For example, in video localization, the core components include various layers, such as video perception, language processing, audio generation, subtitle and metadata, and workflow orchestration.
What are the challenges in AI agent architecture?
AI agent architecture has some challenges, such as coordination between internal agents, scalability across languages, and quality assurance. With continuous upgrades, the AI agent architecture will be able to address these challenges.
What is the difference between a multi-agent and a single-agent architecture?
In a single-agent architecture, one AI agent handles all tasks, while in a multi-agent architecture, there are multiple AI agents with different tasks that collaborate to achieve the goal.
Conclusion
An AI agent architecture has an important role in determining the AI agent's workflow. It must be carefully designed to ensure that each element and agent in the workflow will work together seamlessly. In video localization, an AI agent architecture can consist of various layers. One of the tools with a simple and efficient AI agent architecture is VMEG AI. Its AI Agent for video localization is easy to use, making video localization easier. This is an ideal tool for those who are looking for a tool that is ideal for all skill levels and various projects.
The VMEG Team
Behind VMEG stands a passionate team of creatives, engineers, and language lovers. At the crossroads of AI and storytelling, they craft tools that bridge languages and cultures.